

客户
本案例研究面向使用基于 ARM 的硬件平台并寻求 (a) 增加对较新人工智能模型的支持 (b) 优化人工智能模型在 ARM 后端上的性能的公司。由于这些公司的目标是在 ARM CPU 上验证、剖析和增强人工智能模型的执行,因此需要先进的工具来确保高效推理并最大限度地提高性能。MulticoreWare 的创新解决方案 Perfalign 可帮助开发人员深入了解人工智能模型及其性能特征,并提供交互式可视化功能,从而满足这一需求。
概述
Perfalign 是一个统一的工具包,旨在通过提供用于可视化、功能验证、剖析和性能分析的集成工具来简化人工智能模型开发。它通过提供深入的性能洞察、利用高效的调试工具缩短开发时间以及加速上市战略,简化了人工智能软件栈的优化流程。Perfalign 是为增强 ARM NN 后端性能调优而定制的,它展示了与专用硬件平台保持一致的能力。
挑战
针对不同硬件平台优化人工智能模型是一项独特的挑战,尤其是在确保推理的高效执行和性能调整方面。优化过程通常是手动、迭代和耗时的,需要调试和验证。开发人员需要能详细了解模型执行、数值精度和层级性能指标的工具。可视化模型转换和优化效果是一项重大挑战,因为开发人员需要清楚地了解各种优化带来的变化。
主要挑战包括
- 理解模型优化如何改变执行行为
- 识别优化过程中引入的数值偏差
- 按层分析执行时间以检测瓶颈
- 缩短手动分析、调试和性能调整所需的漫长周期时间
- 有效可视化模型执行行为和优化影响

解决方案
为应对这些挑战,Perfalign针对ARM NN进行了定制,整合了依赖硬件的分析和验证功能。该定制旨在为开发人员提供有关执行行为、数值精度和性能瓶颈的可操作洞察。关键增强功能包括功能验证器,用于深入比较图、节点映射以及使用均方误差(MSE)或皮尔逊相关系数(PCC)进行逐层精度评估。还进行了分析器集成,以跟踪每层的执行时间并识别低效之处。
技术概述
Perfalign 的架构支持针对各种硬件平台的模块化和可扩展定制。与 ARM NN 的集成侧重于以下组件:
功能验证器
一种用于比较原始模型及其优化版本的工具,突出显示节点转换、结构修改,并进行逐层精度分析。
分析器
与 ARM NN Profiler 集成,以微秒为单位跟踪各层执行时间,使开发人员能够通过精确定位瓶颈来微调性能。
这些模块协同工作,为基于 ARM CPU 的人工智能模型执行提供量身定制的完整性能分析框架。
解决方案亮点
Perfalign 针对 ARM NN 的定制提供了多项关键功能:
1. 图比较与节点映射
- 识别原始模型图和优化模型图之间的差异。
- 突出显示层融合、删除和转换。
- 提供有关ARM NN特定优化及其影响的见解。

2. 功能验证器——通过MSE/PCC评估精度
- 该模块通过在层级别测量数值偏差,帮助高效调试。
- 验证器评估优化对模型输出的影响,并确保性能提升不会损害模型的保真度。
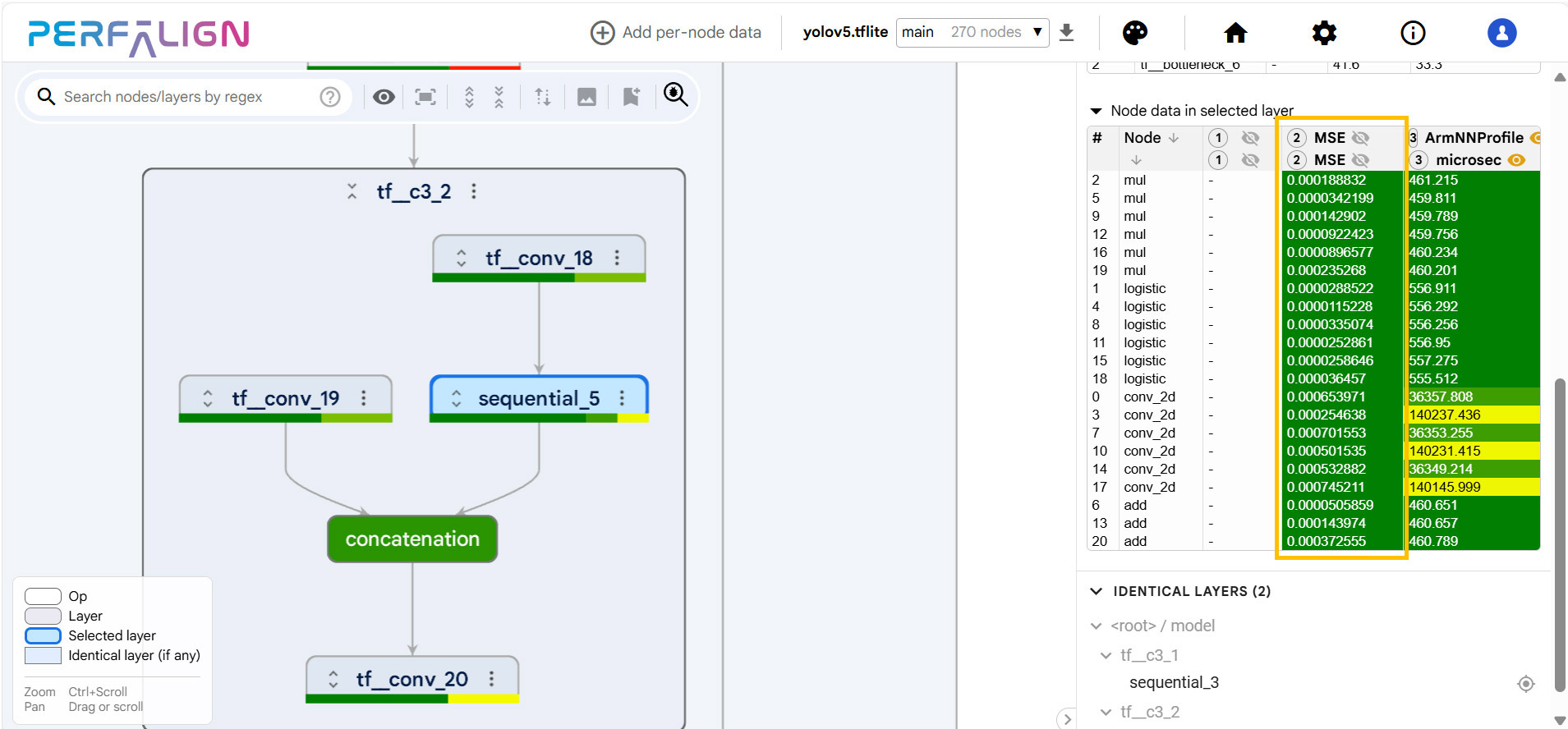
3. 分析器——逐层执行分析
- 跟踪每层的执行时间,以精确定位低效之处。
- 识别瓶颈并提供数据驱动的优化指导。
- 帮助开发人员优化模型执行,提高推理速度。

业务影响
为ARM NN定制的Perfalign带来了显著的益处,包括:
- 增强的性能分析:开发人员获得了对模型执行的详细视图,从而能够进行精确的性能调整。
- 加速的优化工作流程:集成的验证和分析工具简化了针对ARM CPU的模型优化。
- 缩短的调试时间:对数值精度和执行时间的细致洞察减少了调试工作量。
- 可扩展性:定制方法为将类似优化扩展到其他硬件架构奠定了基础,增强了Perfalign的适应性。
结论
通过为 ARM NN 定制 Perfalign,我们成功增强了其在 ARM CPU 硬件上分析、优化和验证人工智能模型的能力。功能验证器和剖析器模块的集成为分析模型转换和优化执行创建了一个强大的框架。这一定制增强了 ARM NN 上的性能调整,展示了 Perfalign 对不同硬件平台的适应性,并巩固了其作为人工智能模型开发和性能分析多功能工具包的地位。
其可扩展设计允许在其他硬件平台上进行类似的调整。有兴趣进一步了解 Perfalign?请通过 info@multicorewareinc.com. 联系我们的团队。


