作者:
Selventhiran Rengaraj 是 MulticoreWare 的技术与项目架构师,负责领导智慧城市、智慧医疗和工业 4.0 领域的解决方案交付工作。他在机器人技术方面拥有丰富的实践经验,并专精于在嵌入式半导体平台上优化人工智能和感知系统。
引言:超越十亿参数竞赛
当今关于人工智能的讨论往往聚焦于规模。头条新闻关注的是更大的模型、更多的参数,以及日益强大的计算和GPU集群。从万亿词元的训练运行到数十亿美元的基础设施投资,这些进展正在推动人工智能在云端和计算密集型生态系统中所能实现的极限。
与此同时,另一场变革正在悄然发生,它将这些能力从数据中心延伸到了物理世界。
工程师们不再仅依赖集中式智能,而是将人工智能嵌入功耗不足1瓦的设备中。这就是边缘智能的世界,其目标并非通用推理或开放式对话,而是在数据源头实现快速、高效且自主的决策。
硬件:专用芯片与微型NPU的崛起
长期以来,微控制器并非为人工智能工作负载而设计。它们专为控制逻辑、信号处理和确定性任务而打造,虽然可靠且高效,但并不适合神经网络所需的并行计算。如今,这种情况正开始发生改变。
业界正稳步向领域专用架构转型。这类处理器专为AI运算设计,而非通用计算。这场变革的核心是微型NPU:一种直接集成于微控制器中的紧凑型神经处理单元。
Arm Ethos-U85等现代案例展示了NPU如何与嵌入式CPU紧密耦合,从而实现高效的设备端推理。这些NPU针对矩阵乘法和卷积等运算进行了优化,其每瓦性能表现优于在通用CPU上运行相同工作负载。
处理器内核本身也在不断演进。以低功耗和确定性运行著称的 Arm Cortex-M 系列,如今已包含支持 SIMD 风格计算的向量处理扩展。这使得音频分析和轻量级视觉流水线等工作负载在 MCU 上变得更加切实可行。
内存架构同样至关重要。高效的 DMA、优化的缓存使用以及细致的 SRAM 管理,有助于确保模型数据流畅传输,同时避免处理器停滞或增加功耗。在功耗低于1瓦的系统中,每次内存访问都至关重要。
软件:连接模型与芯片
仅靠硬件无法实现这一目标。真正的挑战在于,如何将那些在资源丰富的环境中训练出的模型,转化为能在资源受限的微控制器上高效运行的版本。这一转换层正是工程工作的重中之重。
大多数人工智能开发都始于 PyTorch 或 TensorFlow 等框架。这些模型通常采用浮点精度构建,并针对充足的计算资源进行设计,而微控制器(MCU)却无法提供这两者。弥合这一差距需要一套专门的编译器、运行时和内核库。
像 Arm Vela 这样的编译器工具链将神经网络映射到硬件上,决定哪些层在 NPU 或 CPU 上运行,同时处理调度和内存管理。这直接影响性能和能效。
对于未配备 NPU 的设备,CMSIS-NN 等优化库通过 SIMD 和底层优化技术,帮助从 Cortex-M CPU 中实现最大性能。ExecuTorch 和 TensorFlow Lite Micro 等轻量级运行时则通过去除不必要的框架开销,实现高效推理。
这些工具共同架起了训练模型与量产 MCU 之间的桥梁。
优化前沿:让人工智能就绪于嵌入式系统
这个领域最引人入胜之处,或许在于其所需的优化程度。在微控制器上运行人工智能不仅仅是一个部署问题,更是一项设计挑战。
与资源丰富的云环境不同,嵌入式系统在严格的限制条件下运行:仅有几千字节的内存、有限的计算周期以及紧张的功耗预算。
为应对这些限制,开发者依赖于一套面向硬件的优化技术:
- 量化技术将数值精度从浮点(FP32)降至INT8甚至INT4等整数格式。这能显著缩减模型体积和计算负载,且通常对精度影响甚微。
- 剪枝技术可移除神经网络中冗余或不重要的连接。通过削减多余参数,模型得以变得更小、运行更快,同时不牺牲实质性能。
- 运算融合将多个操作合并为单一步骤。例如,合并卷积层与激活层,或重构图结构以消除冗余的广播操作,从而减少内存传输并提升效率。
结合具体硬件目标综合应用这些技术,能获得最佳效果。通用优化的模型几乎总是表现逊于针对其运行的特定微控制器(MCU)进行优化的模型。
重塑产业:人工智能赋能的微控制器(MCU)的影响
将智能转移到边缘的意义,比乍看之下更为切实。
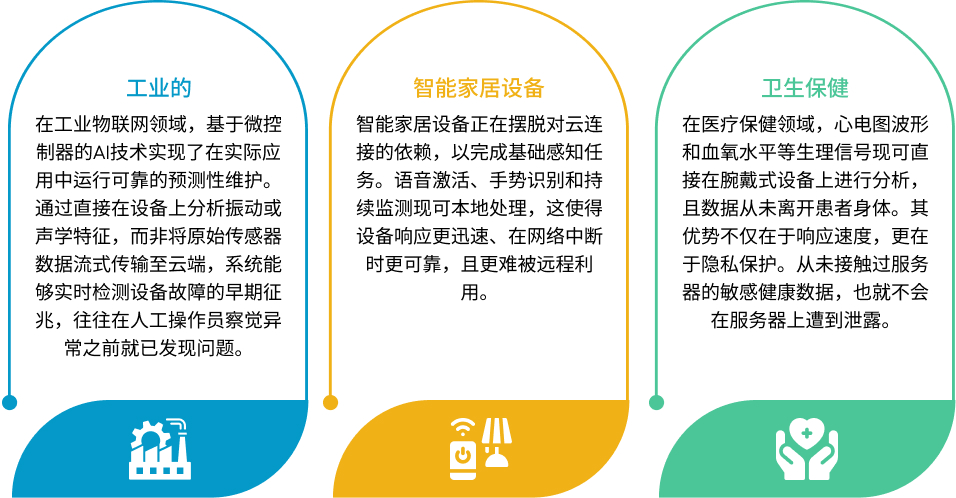
在所有这些领域中,有一个共同点:数据源头的智能化不仅改变了效率,更改变了可能性。
MulticoreWare 如何在 MCU 上实现边缘 AI
凭借在 TinyML 和嵌入式系统领域的深厚专业知识,MulticoreWare 提供专为低功耗 MCU 级 SoC 量身定制的高性能边缘 AI 解决方案。
- 端到端边缘 AI 部署:从模型训练和量化到设备端推理,MulticoreWare 提供专为 Cortex-M 级 MCU 量身定制的完整管道。
- 深度软件优化:凭借在 CMSIS-NN、TFLite Micro 以及低级 ISA 调优方面的专业知识,确保在严格的功耗和内存预算内实现最大性能。
- 定制化用例开发:在语音、视觉和基于传感器的 AI(例如关键词检测、异常检测、TinyML NLP)领域提供经过验证的解决方案,并针对实际部署进行了优化。
- 平台启动与工具链集成:提供对 SDK、编译器和运行时的全面支持,实现跨 MCU 系列的无缝集成、性能分析与扩展。
结论:自主化的新时代
嵌入式系统的未来属于智能微控制器(MCU)。随着我们不断拓展这些微型芯片的能力边界,”低功耗”与”高性能”之间的界限正日益模糊。在 MulticoreWare,我们始终站在这一变革的最前沿,助力合作伙伴驾驭人工智能算法与嵌入式硬件的复杂交汇点。
从智能传感器到自主系统,我们正将”物联网”转变为”智能物联”。
如果您正在探索如何将人工智能引入资源受限的设备,或苦于让模型在低功耗的MCU级SoC上真正运行,这正是MulticoreWare能够为您提供帮助的地方。
立即联系我们,了解MulticoreWare如何助力您的边缘AI之旅。