

客户
该客户是一家专注于视觉DSP的知识产权公司,其产品广泛应用于图像处理、计算机视觉和人工智能领域。
挑战
该项目的目标是在客户的视觉DSP上执行端到端 Inception-V3 卷积神经网络(CNN)图像分类模型的推理任务。
解决方案
该项目利用了一系列工具和技术,包括 C/C++、量化(Quantization)、卷积神经网络推理、DSP intrinsic(内联函数)、DMA(直接内存访问)和分块(tiling)算法。
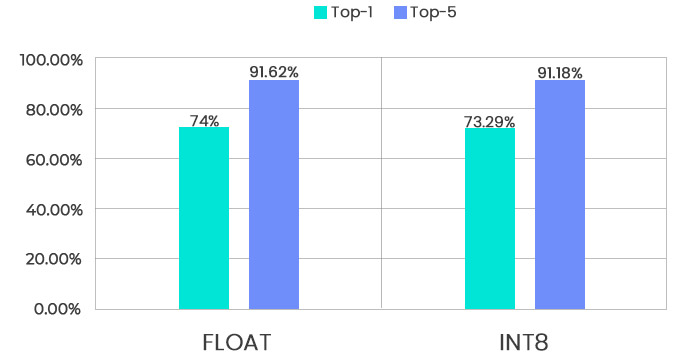
我们成功地应用了基于 ImageNet 数据集训练的 Inception-V3 浮点模型,实现了 74% 的 Top-1 准确率和 91.62% 的 Top-5 准确率。随后,我们使用 MulticoreWare(迈凯伦)定制的量化算法将浮点模型量化为 INT8 数据类型。紧接着,针对 INT8 数据类型实现了基于 x86 的参考 Inception-V3 执行流程。
浮点与8位量化模型的Top-5 / Top-1分类准确率
MulticoreWare 为视觉 DSP 手动优化了 Inception-V3 模型中的各个层/操作,创建了一个端到端的基于内联函数的执行流程,同时使准确率与基于 x86 的 INT8 流程相匹配。考虑到 Inception-V3 中的层数众多以及DSP片上数据内存有限,我们精心设计并实现了DMA和数据分块算法,以高效管理从外部内存到片上内存的数据传输。
定制量化逻辑:
MulticoreWare 的解决方案拥有定制的量化逻辑,确保量化模型的 Top-1 和 Top-5 分类准确率损失最小。我们使用 DSP 内联函数技术手动优化了 Inception-V3 模型的大约 94 个层,获得了与理论性能估计非常接近的结果。此外,我们的团队还实现了输入/输出/权重的分块,并构建了一个端到端的 Inception-V3 优化流程,有效地隐藏了 DMA 数据传输的延迟。
卷积神经网络模型:Inception-V3 (使用 Imagenet 数据集预训练)
| 卷积神经网络架构详情 | |
|---|---|
|
卷积层数量
|
94 |
|
级联层数量
|
11 |
|
池化层数量
|
14 |
商业影响
MulticoreWare 的努力使客户能够在保持与浮点模型精度相似的 Top-1 和 Top-5 准确率水平的前提下,对 299x299x3 尺寸的输入图像实现 30 FPS 的处理速度。这为客户向其用户展示产品性能提供了极佳的演示案例。
| 内存建模 - DDR延迟[时钟周期] | FPS |
|---|---|
|
100 |
30.42 |
|
0 |
31.09 |
结论
本案例研究彰显了MulticoreWare在量化和DSP方面的专长。如需更全面地了解我们的解决方案和服务,请通过 info@multicorewareinc.com 联系我们。


