
作者Guru Narayan C 是 MulticoreWare Inc. 计算事业部的产品经理。Guru 拥有十多年的专业经验,其中五年专注于产品管理。他具备丰富的技能,包括产品营销、管理、路线图规划、分析、敏捷方法、Scrum、数字化转型和敏捷项目管理。
简介
确保最佳性能对于提供快速、准确和高效的 AI 解决方案至关重要。性能分析和瓶颈识别是帮助开发人员了解系统行为并确定需要改进的领域的关键实践。这些实践与提高生产力直接相关,正如我们之前的博客文章所强调的那样。
通过优化性能、确保可靠性和促进协作,开发人员可以推动 AI 驱动应用程序的创新。这篇博文探讨了关键性能指标、分析的最佳实践和 AI 工作流中的常见瓶颈,以及克服这些瓶颈的策略。
了解 AI 工作流中的性能分析
性能分析涉及系统地测量和评估软件堆栈中不同组件的效率。此过程有助于确定哪些改进可以提高 AI 模型的整体速度、准确性和资源利用率。监控关键性能指标可以清晰地了解 AI 模型的性能,并突出显示需要优化的领域。这些指标包括:
- 延迟: 测量 AI 模型处理输入并产生输出所需的时间。对于实时应用而言,低延迟非常重要。
- 吞吐量: 指 AI 系统在给定时间范围内可以处理的任务数。高吞吐量表示处理效率高。
- 资源利用率:跟踪模型训练和推理期间计算资源(CPU、GPU、内存、AI 加速器)的使用情况。最佳利用率可确保资源不被浪费。
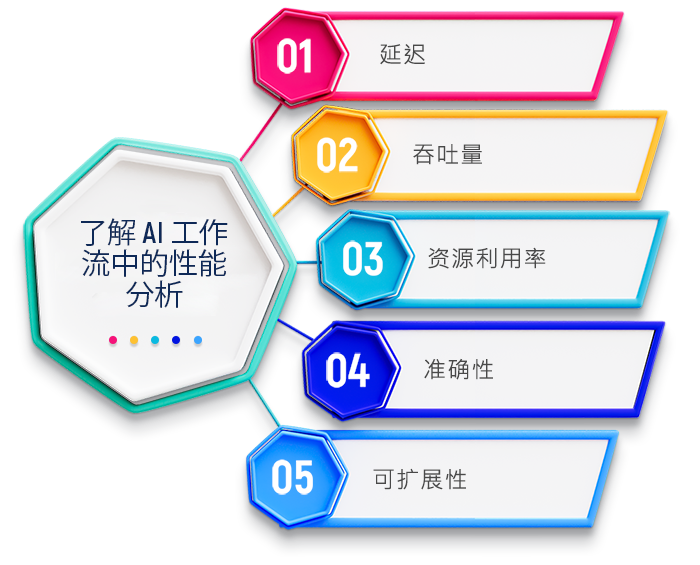
- 准确性:AI 模型预测的正确性通常需要与延迟等性能指标相平衡。
- 可扩展性:AI 系统在工作负载增加时保持性能水平的能力。
了解 AI 工作流中的性能分析
性能分析涉及系统地测量和评估软件堆栈中不同组件的效率。此过程有助于确定哪些改进可以提高 AI 模型的整体速度、准确性和资源利用率。监控关键性能指标可以清晰地了解 AI 模型的性能,并突出显示需要优化的领域。这些指标包括:
- 延迟: 测量 AI 模型处理输入并产生输出所需的时间。对于实时应用而言,低延迟非常重要。
- 吞吐量: 指 AI 系统在给定时间范围内可以处理的任务数。高吞吐量表示处理效率高。
- 资源利用率:跟踪模型训练和推理期间计算资源(CPU、GPU、内存、AI 加速器)的使用情况。最佳利用率可确保资源不被浪费。
- 准确性:AI 模型预测的正确性通常需要与延迟等性能指标相平衡。
- 可扩展性:AI 系统在工作负载增加时保持性能水平的能力。
性能分析的最佳实践
- 定义明确的性能目标: 根据应用程序的要求建立具体的性能目标。这些目标应涵盖所有关键指标,包括延迟、吞吐量和资源利用率。
- 基准性能测量: 测量当前性能以建立基准。这有助于比较改进并了解优化工作的影响。
- 迭代测试和改进: 采用迭代方法进行测试和改进。定期测试 AI 模型,分析性能数据并改进模型以解决已发现的问题。
- 关注端到端性能: 考虑从数据输入到最终输出的整个 AI 管道。优化每个阶段,以确保工作流程某一部分的性能改进不会对其他部分产生负面影响。
- 真实世界测试: 在与真实世界条件非常相似的环境中进行性能测试。这可确保 AI 模型在实际部署场景下表现良好。
识别和分析瓶颈
瓶颈可能来自各种原因,包括算法效率低下、硬件利用率不理想以及资源管理不善。识别和解决这些问题对于提高整体系统性能至关重要。
克服常见瓶颈的策略
数据 I/O 瓶颈:缓慢的数据输入/输出操作会严重影响 AI 模型的性能。这通常是由于数据加载管道效率低下或存储解决方案缓慢造成的。
解决方法:实施高效的数据加载管道,使用数据缓存策略,并利用高速存储解决方案。考虑预处理数据以减少模型训练和推理期间的即时计算。
硬件组件利用不足/过度:CPU、GPU 和 AI 加速器等硬件组件的利用率不足会导致性能低下。过度利用会导致过热和节流,而利用不足会导致资源浪费。
解决方法:监控和平衡所有硬件组件的工作负载,以确保高效利用。使用动态负载平衡技术并根据实时性能指标调整资源分配。
内存瓶颈:内存不足或内存使用效率低下会阻碍模型训练和推理,导致性能下降或崩溃。
解决方法:通过减小模型大小、使用内存高效的数据结构以及采用模型修剪和量化等技术来优化内存使用。确保有效管理内存以避免泄漏和溢出。
算法效率低下:优化不佳的算法可能是性能下降的主要原因。这可能包括低效代码、冗余计算或非并行化进程。
解决方法:重构和优化算法,尽可能并行计算,并消除冗余计算。使用针对性能进行了优化的高效库和框架。
网络延迟:在分布式 AI 系统中,高网络延迟会减慢不同组件之间的通信速度,从而影响整体性能。
解决方法:优化数据传输协议,使用高带宽网络,并尽量减少组件之间传输的数据量。考虑数据压缩和智能数据路由技术。
性能分析工具
目前,AI加速器生态系统中的性能分析工具分散且尚未完全开发。这种碎片化的环境使开发人员难以全面分析性能并识别瓶颈。许多工具仅解决特定的性能方面或专注于特定硬件,缺乏整体分析所需的集成方法。
为了解决这一差距,我们开发了全面的工具,将所有性能分析功能整合到一个地方。我们的目标是提供一套统一的工具,以促进详细的性能监控、高效的瓶颈识别和有效的优化策略,最终提高AI软件开发人员的生产力。

结论
性能分析和瓶颈识别是成功AI开发的关键组成部分。开发者通过关注关键指标和最佳实践,解决瓶颈问题,可以确保AI模型的最佳效率,获得稳健而准确的结果。
敬请关注,我们将继续创新,支持AI开发社区,提供集成的强大性能分析解决方案。请通过 info@multicorewareinc.com 与我们联系。


