作者 Reshi Krish 是MulticoreWare 公司平台与编译器技术部门的软件工程师,专注于为资源受限平台构建超高能效的人工智能流水线。她擅长在多样化硬件环境中优化和部署人工智能,运用量化、剪枝及运行时优化等技术。其工作涵盖线性代数库优化、嵌入式系统及边缘人工智能应用领域。
引言:突破功耗限制的创新驱动力
随着人工智能以前所未有的速度持续发展,其日益增长的复杂性往往需要强大的硬件和高能耗资源。然而,在将人工智能解决方案部署到边缘时,我们寻求能够以最低能耗运行的超高效硬件,这带来了独特的工程挑战。ARM Cortex-M微控制器(MCU)及同类低功耗处理器存在严苛的计算与内存限制,使得量化、剪枝及轻量化运行时等优化技术对实时性能至关重要。这些挑战反过来也催生了创新的解决方案,从而让人工智能变得更易获取、更高效、更具可持续性。
在MulticoreWare,我们持续探索多种路径,将更多智能推向这些资源受限的设备。这一探索引领我们进入神经形态AI架构领域,并开发出专用的类脑硬件——通过模拟大脑的事件驱动处理机制,实现超低功耗推理。我们洞察到该框架的创新价值,决心将其与深厚的MCU技术积淀相结合,为医疗、智能家居及工业领域开辟持续在线AI的新路径。
面向神经形态硬件的设计
我们所确定的神经形态人工智能框架采用了一种新型神经网络——时序事件神经网络(TENNS)。TENNS采用状态空间架构,能够动态处理事件而非固定间隔处理,通过跳过空闲期来最大限度降低能耗和内存占用。该设计可在毫瓦级功耗下实现实时推理,使其成为边缘部署的理想选择。
开发神经形态AI模型远非简单移植现有架构。我们采用的框架要求实现完整的 int8 量化,并遵守严格的架构约束:仅支持有限的网络层类型,且模型必须遵循固定的层序列以确保兼容性。这些限制往往需要重大重构,包括修改模型架构、替换不支持的激活函数(如LeakyReLU→ReLU)以及简化分支拓扑结构。诸如多输入/输出模型等深度学习特性同样无法实现,开发者需实施替代方案或彻底重构模型。
简而言之,为神经形态硬件进行开发意味着从头开始,在精度、效率与严格的设计规则之间取得平衡,从而兑现其在边缘实现实时、超低功耗人工智能的潜力。
在边缘设备上实现实时老人辅助系统
为展现类脑人工智能的潜力,我们开发了一套基于计算机视觉的老人辅助系统。该系统能在极低功耗硬件上实时运行,可检测坐立、行走、躺卧或跌倒等关键人体活动。
目标简单而雄心勃勃:
构建完全基于设备的低功耗AI流水线,在资源受限环境中持续监测并解析人体动作,同时保障用户隐私与运行效率。
然而受框架架构限制,某些模型(如姿态估计)无法完全支持。为此我们采用混合方案,融合类脑与传统计算资源:
- 神经形态硬件:通过专用模型执行物体检测与活动分类
- CPU(Tensorflow Lite):处理姿态估计与中间特征提取
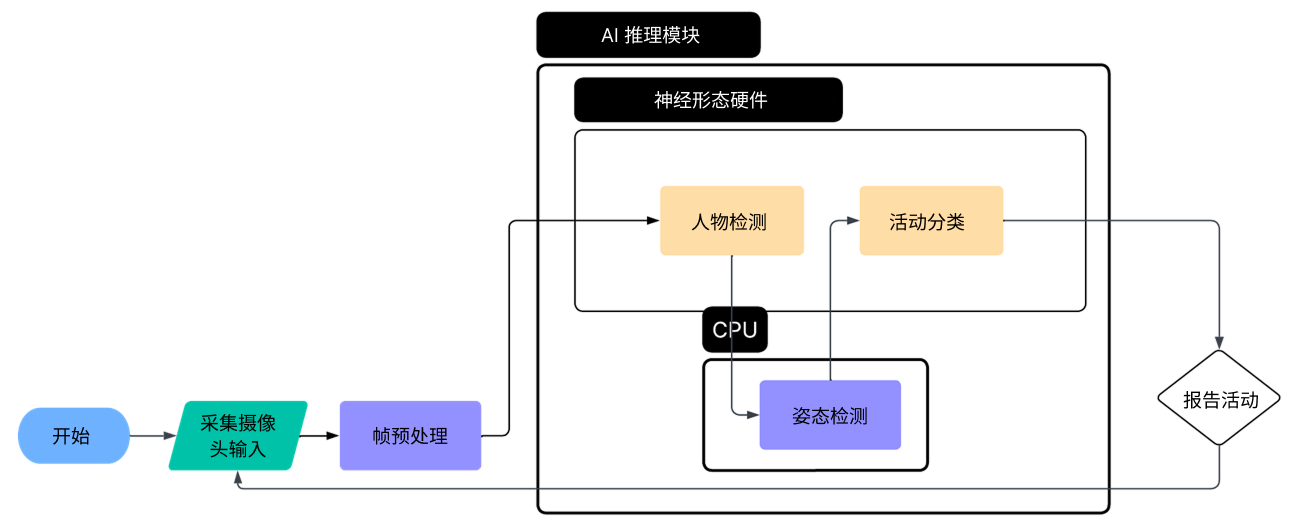
该设计在保持功能完整的同时,也确保了边缘侧推理的高能效。我们的模块化视觉流水线利用类脑加速技术进行检测和分类,而姿态估计则在主设备上运行。
成果:边缘智能低功耗辅助系统
在上述演示中,我们成功在树莓派上部署了完整的视觉处理流水线,该设备通过PCIe插槽连接神经形态加速器,实现了无缝运行。这充分证明了该系统的可移植性与实际部署能力,验证了在边缘设备上实现实时低功耗人工智能的可行性。该系统可持续实时识别并分类用户活动,可即时检测跌倒或求助手势等事件并触发紧急警报。所有处理均在边缘端完成,确保关键安全场景中的隐私保护与响应能力。
神经形态架构仅消耗传统深度学习流水线的极小功耗,同时保持稳定的推理速度和强健性能。
- 超低功耗
- 便携式树莓派+神经形态硬件配置
- 端到端应用在边缘硬件上运行
打造真正低功耗边缘AI的实践指南
MulticoreWare在新兴低功耗计算生态系统中运用深厚的技术专长,使AI能在资源受限的平台上高效运行。我们的解决方案融合:

- 面向低功耗 MCU 的应用就绪型 AI 工作负载:唤醒词/关键词触发语音模型、紧凑型视觉(人物检测、分类)、传感器级异常检测及微型机器学习自然语言处理,均针对Arm Cortex-M及同类低功耗嵌入式芯片优化。
- 端到端 SDK 赋能:提供定制的 CMSIS-NN 算子、清晰从训练到 TFLite 的转换流程,以及结合内存剖析的定向量化与剪枝技术,确保在 MCU 上的顺利部署。
- 编译器级与运行时优化:利用TFLite Micro和TVM-Micro调优内核,管理内存紧凑张量空间,构建能在严格RAM、计算和功耗预算内保持稳定的推理路径。
更广泛的 MCU 人工智能应用:工业、智能家居与智慧城市
随着医疗健康领域引领嵌入式优先的人工智能转型,智能家居、工业系统和智慧城市正迅速跟进。质量检测、预测性维护、机器人辅助、家庭安防和在场感知等应用日益需要直接在MCU级低功耗边缘处理器上运行的AI技术。
MulticoreWare为Arm Cortex-M设备打造的实时推理框架,通过高度优化的流水线支持这一转型,包括量化、剪枝、CMSIS-NN内核调优,以及为资源受限MCU定制的内存紧凑执行路径。这使OEM厂商能够部署唤醒词检测、紧凑视觉模型和传感器级异常检测等工作负载,让最微型设备也能运行智能功能,无需依赖外部计算资源。
结论:云端之外的智能新定义
人工智能与嵌入式计算的融合,标志着智能设计、部署与扩展方式的重大变革。通过在边缘端直接实现轻量化、高能效的人工智能,MulticoreWare助力医疗、工业及智慧城市领域的客户实现更快的响应速度、更高的可靠性及更低的能耗足迹。
随着计算与智能的边界日益融合,MulticoreWare 针对 MCU 及嵌入式平台的边缘 AI 赋能方案,确保我们的合作伙伴能够保持领先,为构建一个真正去中心化、超越云端的实时智能未来奠定基础。
欲深入了解MulticoreWare边缘AI计划,请发送邮件至info@multicorewareinc.com。